カイ二乗検定と Kruskal-Wallis 検定は同様な検定である
井口豊(生物科学研究所,長野県岡谷市)
最終更新: 2022 年 12 月 15 日
1. はじめに
ノンパラメトリック検定の中でも,カイ二乗検定と Kruskal-Wallis 検定は良く知られた検定法である。一般的には,前者は母比率の差の検定であり,後者は平均順位の検定と言われる。ただし後者は,中央値検定であるかのような誤解があるので,その点は注意が必要である。
このように両者は,全く異なる目的の検定であるかのように説明されるが,実際には,似た者同士なのである。
例えば, A, B, C の 3 群に,はい,いいえ
,という二件法アンケートを実施して,その結果をまとめたクロス集計表データ(表 1)を考えて見る。
単純に考えると,はい・いいえの比率を比較する検定として,カイ二乗検定が考えられる。
しかしながら,はい・いいえは二値データであり,ダミー変数 0, 1 としても扱え,そうすると,順序尺度(順位データ)とも考えられ,そうすると, Kruskal-Wallis 検定も適用できるのである。
ここでは, R を使い,シミュレーションでカイ二乗検定と Kruskal-Wallis 検定の p 値を比較してみた。
なお,Kruskal-Wallis 検定は,通常,近似検定で計算されるので,各群の標本サイズ(サンプルサイズ)が小さいと,正確な結果が得られないので注意しよう。
2. カイ二乗検定と Kruskal-Wallis 検定の p 値の変化
データは 3 群(サンプル数 3)で,それぞれセルのサンプルサイズ を 15 から 40 で変化させて,両検定の p 値を比較した。
以下が, R スクリプトである。
#############
k<- 1e+2 # 標本取り出し反復回数
p<- replicate(k, {
# 度数データ
x<- sample(15:40, size = 6, replace = T)
# 群分け
group<- factor(rep(
1:3,
c(sum(x[1:2]), sum(x[3:4]), sum(x[5:6]))
))
# 群内順位
d<- factor(rep(rep(1:2, 3), x))
c(
# カイ二乗検定
chisq.test(
matrix(x, ncol = 3),
correct = FALSE)$p.value,
# Kruskal-Wallis 検定
kruskal.test(d ~ group)$p.value
)
})
par(oma = c(3, 3, 2, 2))
# カイ二乗検定と Kruskal-Wallis 検定 p 値
plot(
p[1, ], p[2, ],
xlab = "Chi-square test p-value",
ylab = "Kruskal-Wallis test p-value",
cex.lab = 1.2,
cex.axis = 1.0
)
abline(0, 1, col = "red")
################
結果は,次の図 1 のとおりである。
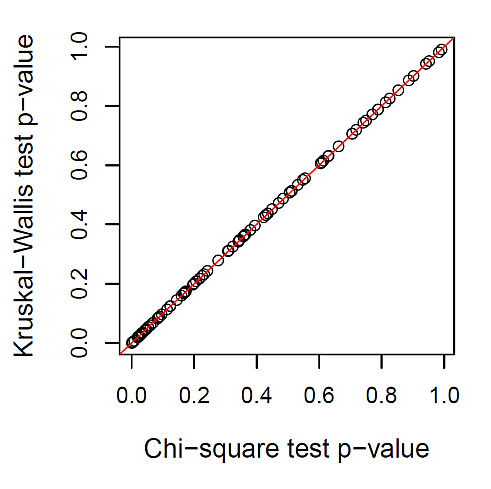
カイ二乗検定と Kruskal-Wallis 検定の p 値が,ほぼ一致することが分かる。両者は,比率の検定でもあり,順位の検定でもあり,その意味で二元性を持っていると言える。